
Quantitative and macroanalytic approaches
What do we know about the authors of the earliest Arabic books in terms of their native origins and linguistic and cultural backgrounds? Were the majority of them Arabic-speaking Muslims from imperial capitals, or non-Arab converts or even non-Muslims? Could this information be useful in tracing the flow and formation of ideas and culture? To answer these questions computationally, one must begin with creating a corpus of texts – in this case the OpenITI – including robust metadata for the texts and their authors. In this blog post, I will discuss the question of the native origins of scholars and authors of early Islamicate society based on a subcorpus of the OpenITI, which includes all the texts in the corpus written within the first five centuries of Islam, ending in 505/1111, al-Ghazali’s death date. More generally, I hope to show how a combination of quantitative and macroanalytic approaches can be useful for the study of premodern Arabic texts and the history of the Arabic book and its authors.
The usefulness of computer-assisted ‘distant reading’ and analysis has been convincingly defended by literary historians including, recently, Franco Moretti and Matthew L. Jockers, who in turn drew inspiration from the fields of economics, geography and the natural sciences.1 Computational methods range from the study of metadata – a set of information about the books and authors in the corpus, the lowest hanging fruits – to more complex text-level analysis. These methods were also adopted and further developed within our own field of Islamic history by Maxim Romanov, as exemplified in his study of al-Dhahabi’s (d. 748/1348) Taʾrikh al-Islam and Ismaʿil Pasha al-Baghdadi’s (d. 1338/1919) Hadiyat al-ʿarifin, which offer relatively structured data on premodern authors and their output, reaching tens of thousands of entries (over 30, 000 biographies in Taʾrikh al-Islam and 40,000 titles in Hadiyat al-ʿarifin).2
Earlier generations of Islamicists were, of course, well aware of the potential of quantitative methods for the study of biographical dictionaries. But whereas earlier attempts were typically limited, not least because of the enormous labour involved in data collection, computational reading of biographical dictionaries enables modern scholars to analyse all biographical dictionaries available in machine-readable format by, for instance, analysing the descriptive names (nisbas) more efficiently or mapping their regional affiliations and travels through the automatic tagging of toponymics.
As noted, a computational study of a modern bibliographical dictionary, the Hadiyat al-ʿarifin, by Maxim Romanov has already addressed the question of cultural production in the Islamic world up to the early modern period. By focusing on a much smaller sample from the OpenITI corpus, books authored during the first five centuries, I hoped to get an idea about the geographical distribution of the historical texts in Arabic through an analysis of the metadata, corpus statistics and text reuse data produced by the KITAB project.
However, the OpenITI corpus did not have any information about the geographical provenance of its authors and books beyond nisbas, a part of Arabic personal names that often contains information about a person’s belonging. To create metadata I combined manual annotation with automatic attribution of birthplaces based on the authors’ nisbas. But nisbas, however informative, may not always accurately represent an individual’s cultural background. A Persian client of an Arab tribe may adopt its tribal nisba without even learning how to speak Arabic, or may keep and pass his Persian family name to his fully Arabised descendants who may settle elsewhere in the world. Likewise, geographic nisbas are also commonly adopted after immigrating to a new place. With these cautions, and with the aim of understanding the present corpus better, I have manually checked reliable reference works and created author birthplace metadata (regions and cities of birth) for most books in the OpenITI corpus (October 2020 release) and for all of the authors who lived in the first five centuries, with the exception of a small number of anonymous texts and translations from Greek. Eventually, the corpus will include accurate geographical data for the places of birth, death, residence, study and travel for all authors in the corpus, which will allow us to create more informative networks and to map cultural and demographic shifts over periods. At this stage, identifying authors’ birthplaces was prioritised as the most stable indicator of a person’s cultural background, for even though both birth and death can happen at a place of temporary residence, birth presumes stronger socioeconomic and thus cultural ties to a place.
Take, for example, al-Tabari, the ʿAbbasid-era polymath, who studied in Iran, Iraq, Hijaz, Syria and Egypt and then spent half a century in Baghdad, a city with which he is rightly associated. Nonetheless, it is undeniable that his first sense of historical time (which evolved over time) must have been provided by the Iranian world, especially his birthplace, Tabaristan – the town of Amul in the region of Daylam, where he grew up, from where he was supported by his family, and which he visited at least twice – and Rayy, where he studied. Likewise, his native origin may have contributed to suspicions of his Shiʿi leanings, as various forms of Shiʿism, especially Zaydism, dominated the Caspian region. In the same way, all other historians that followed him also demonstrate regional perspectives. The crucial disclaimer that I would like to make, however, is that at this stage my priority is to prepare the data, not to interpret it.
A note on the geographical division
The geographical division of the Islamic world that I have adopted comes from al-Thurayya Gazetteer (Maxim Romanov and Masoumeh Seydi),3 which follows Georgette Cornu’s (1985) Atlas du monde arabo-islamique,4 which in turn is based on third–fourth/tenth–eleventh-century Muslim geographical works. In most cases, the classical division of regions is useful. When necessary, several regions can be united into one regional cluster. For instance, for some analyses I have merged Khurasan, Ma Waraʾ al-Nahr and Sijistan into one ‘Greater Khurasan’ cluster. This grouping reflects the integration of these three regions following the Arab conquests and the greater cultural connectivity facilitated under the Tahirid, Saffarid, Samanid and Ghaznavid dynasties. Nonetheless, both historical sources (e.g. Ibn Qutayba) and modern studies stress the ambiguity of the boundaries of Khurasan, which could denote much of the territory to the east of Rayy or Hamadhan when viewed from the Sasanian or ʿAbbasid capital in Iraq.
Thus, I began by creating birthplace metadata (town and region of birth) for the authors in the OpenITI corpus. Currently, native origin has been assigned for all the authors who lived before 505/1111, in most cases down to their town of birth, and this information is now available through our Corpus Metadata App. Other KITAB team members are working towards completing the metadata for all texts in the corpus. The subcorpus of texts from the first five centuries contains 1,947 OpenITI texts. This is far from including all the surviving Arabic books from this period. The digital corpus still represents only a fraction of the published and unpublished materials available to modern scholars of Islam. The good news is that the corpus is expanding rapidly, and the new OpenITI release (2021.1.4) already includes 458 more texts for the early period up to 505/1111 (out of 1,029 new texts for all periods) compared to the previous release, four months earlier in October 2020, that was the basis of my work. The metadata will be updated periodically to reflect these additions.
Introducing the First Five Centuries Power BI app
After creating the metadata, I created a Power BI application to explore the regional distribution of authors in the OpenITI. The app relies on the analysis and visualisation tools offered by MS Power BI. Although the app is still being developed, it can already be used for the purpose of exploring the data. Importantly, as discussed above, the present iteration reflects only the authors’ regions of birth. You can access the App below.
How to use the app:
The app has seven pages:
-
Stats: an interactive overview of the subcorpus, its size in terms of word count and text reuse according to authors’ native origins. It also visualises the distribution of texts and authors by native regions over the first five centuries. There are sliders for adjusting the time periods according to the Islamic and Gregorian calendars. This feature is repeated on other pages, too.
-
Map: an interactive map that will be more informative when more geographical metadata is added. On this page, books can be filtered by word count and AH and CE years.
-
Rise of Books: a diachronic visualisation of the corpus’s distribution by the authors’ native origin and book size (word count). Try using the sliders to filter out shorter works or to select a specific time period.
-
Genre: a preliminary attempt to provide insight into the content of the books by region. By selecting regions you can view prominent tags in the word cloud visualisation on the right. This approach has greater potential once tagging and classification systems have been improved. The current OpenITI tags were created on the basis of Carl Brockelmann’s rather broad classification in Geschichte der arabischen Litteratur (Leiden, 1932–49); in addition, some were introduced by the online digital libraries from which the texts originated or by the individual scholars who added them to the corpus.
-
DeepDive: another attempt to visualise the corpus by the regional distribution of prolific scholars in the corpus. You can select one or several regions for comparison during a specific period of time and can filter for extremely long or short works.
-
Word Count: a simple grouping of books by region and total word count. Al-Scopus ranking in the bottom right shows the most quoted books. Try the sliders to find most frequently quoted books for each century.
-
Text Reuse: text reuse statistics according to the authors’ native regions. Check the Al-Scopus ranking for the top quoted (most reused) authors. The page also includes filters for date and word count and a ranking of authors by reuse.
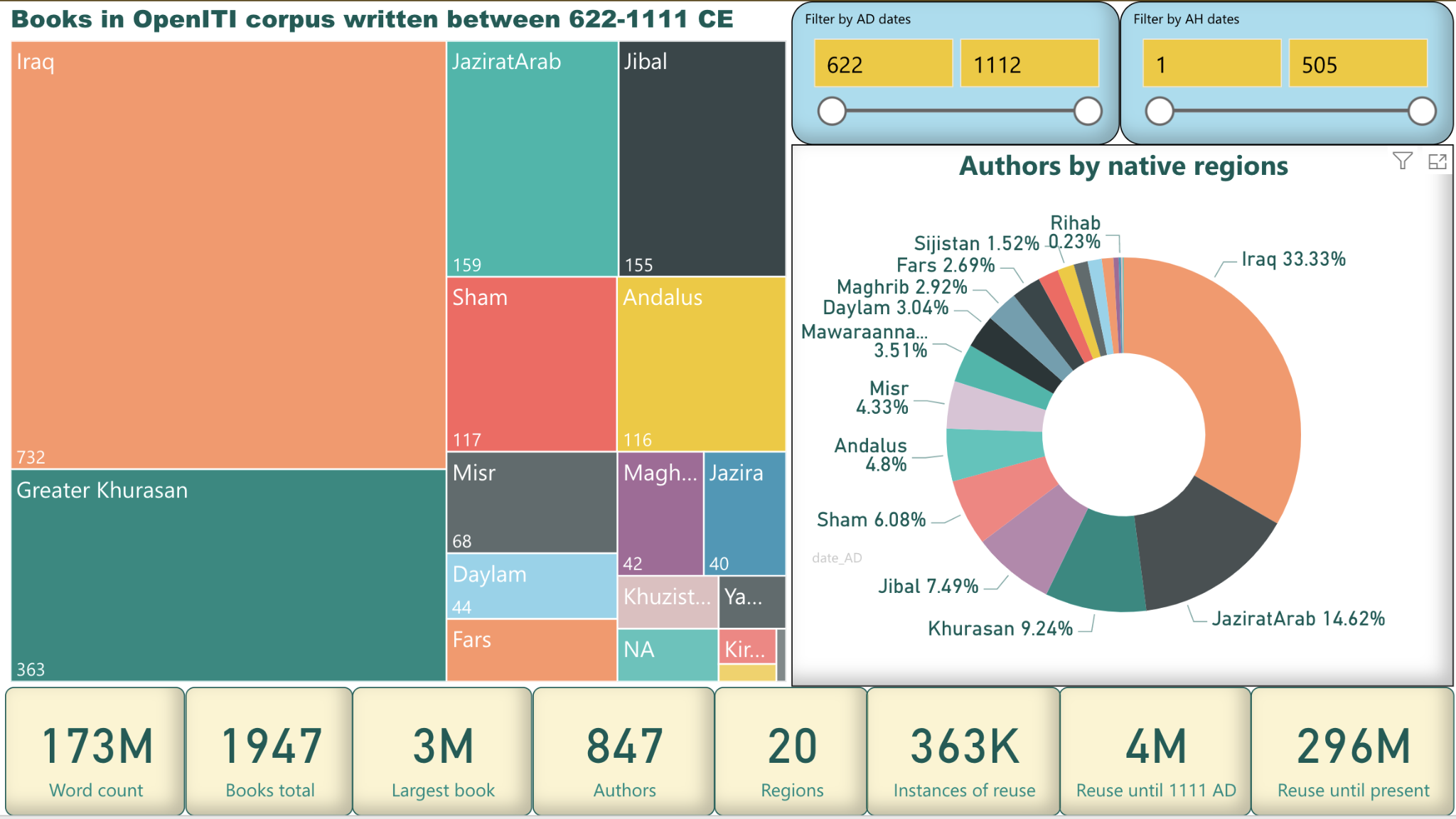
Figure 1: Total statistics. Iraq is the birthplace of the most authors, followed by Jazirat al-ʿArab and Khurasan. However, if you include Ma Waraʾ al-Nahr and Sijistan in the Greater Khurasan region, the eastern region is second only to Iraq in the total number of books as well as of authors. It is also worth noting that the majority of the diwans – poetry collections – from the first century CE and pre-Islamic times are modern reconstructions. If we discount these, the number of authors from the Jazirat al-ʿArab diminishes significantly.
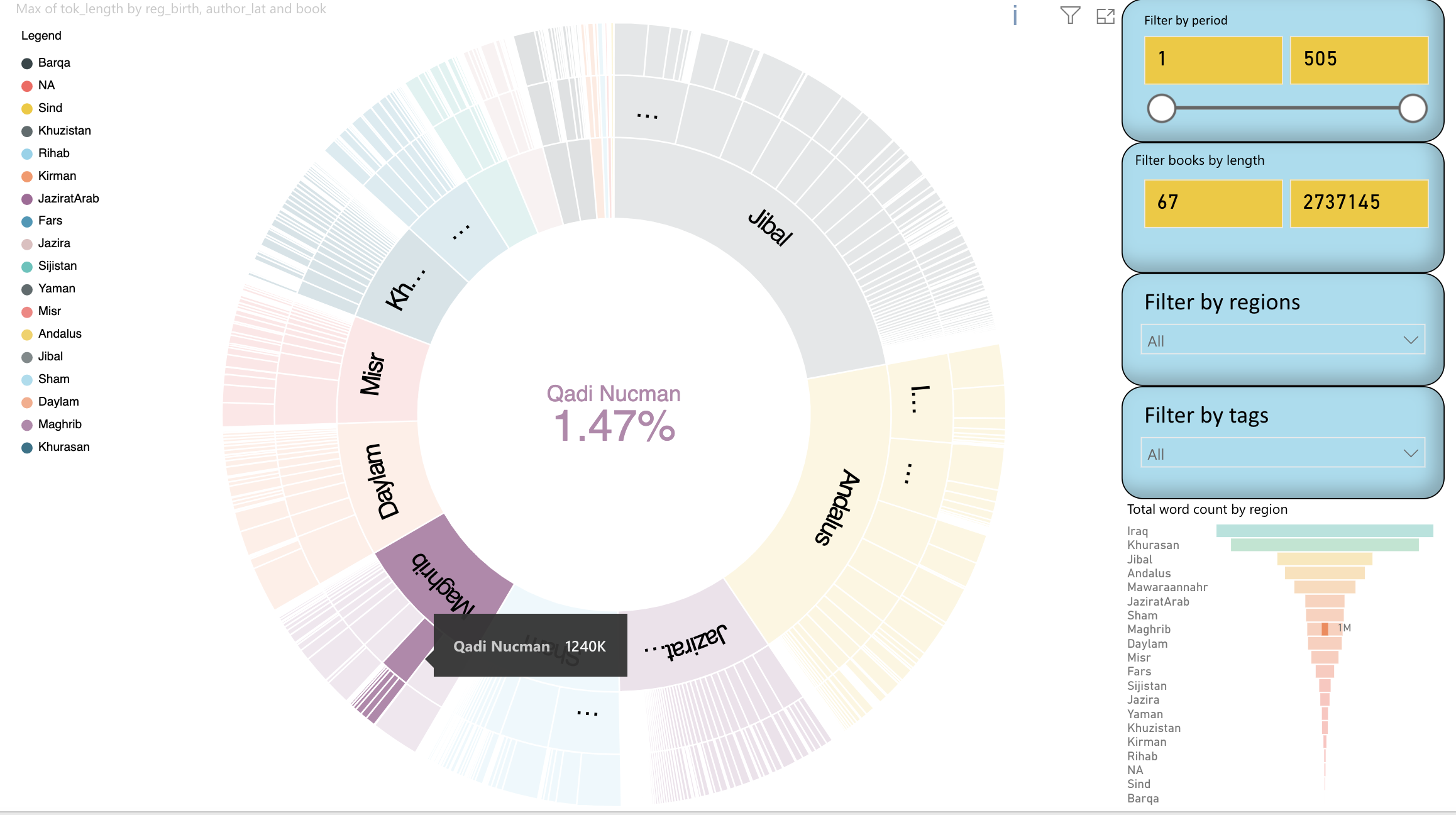
Figure 2: DeepDive allows a focus on individual authors and their output within their geographical clusters. This figure tells us that al-Qadi al-Nuʿman was the second most productive author from the Maghreb in the corpus for the first five centuries, slightly behind Ibn Abi Zayd al-Qayrawani, who wins the race with his massive Kitab al-Nawadir wa-l-ziyadat. However, by looking at the works of al-Qadi al-Nuʿman, specialists will notice that fewer than half of his published works are included in the corpus, and this is not to mention books of his that have not reached us, such as the largest Hadith collection of the time, the Kitab al-Idah. Thus we get an immediate quantitative insight into how prolific al-Qadi al-Nuʿman, the chief judge of the Fatimid Empire, was in comparison with his contemporaries.
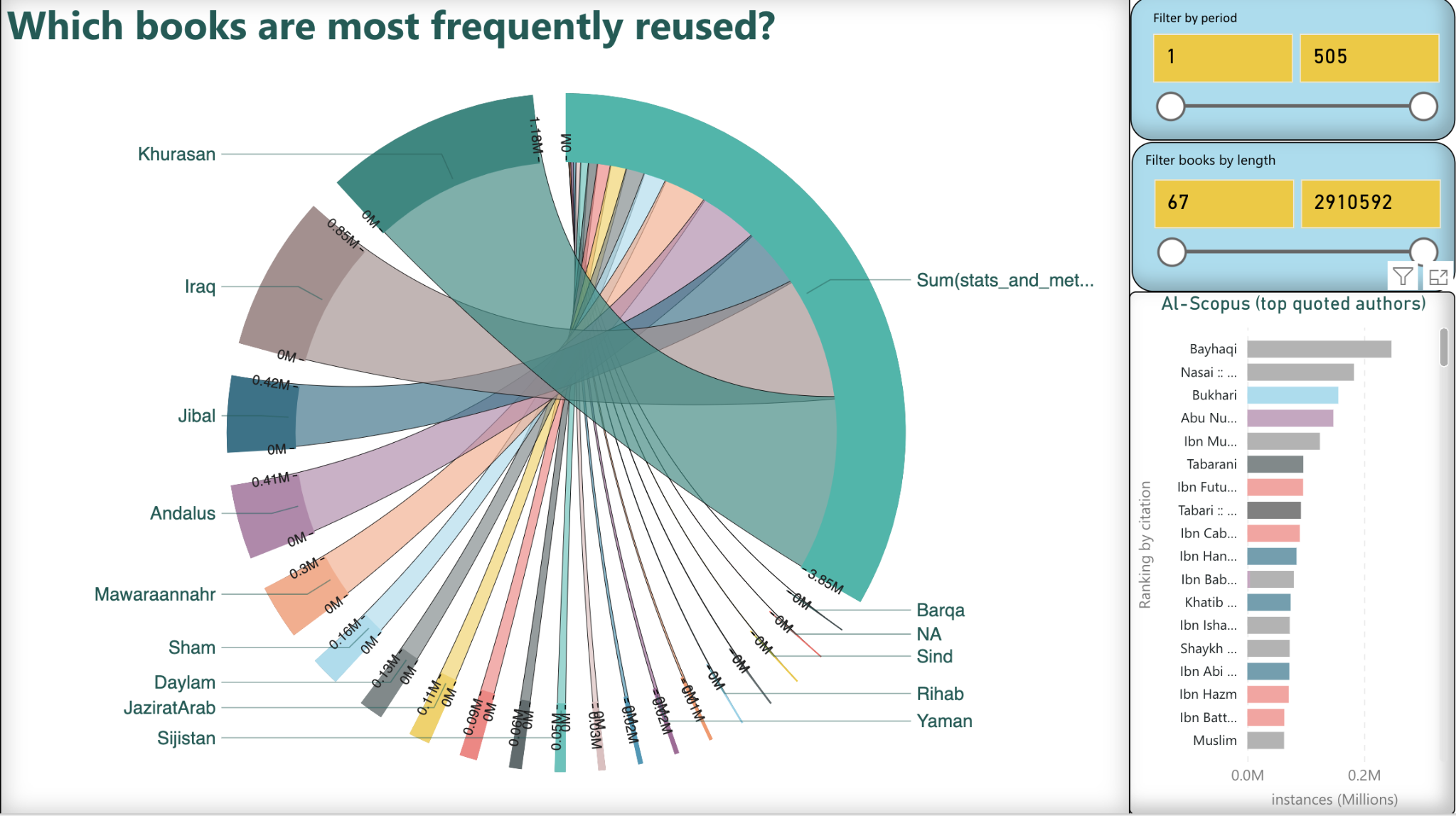
Figure 3: Text reuse statistics show the proportion of all text reuse across the subcorpus attributable to books from specific regions. Khurasan dominates other regions, including Iraq, in terms of the ranking of its books according to text reuse. It is true that Muslims from all over the Islamic empire had settled in the great cities of Iraq, but according to our criteria here they were counted as Iraqis (Iraq accounts for 33% of authors in the first five centuries corpus). Despite this important early start advantage, during and beyond the first five centuries Iraq lags far behind Khurasan in terms of text reuse by other authors. Ma Waraʾ al-Nahr and al-Andalus are two other regions that can boast disproportionate text reuse despite accounting for fewer texts in the corpus. This is clearly due to the Hadith scholarship that flourished in both regions.
I hope these preliminary insights into the regional distribution of early Arabic books will spark some interest and encourage others to contribute to the initiative. The KITAB team values feedback from scholars and students of the Arabic textual heritage and digital humanists. Do get in touch if you have comments or suggestions.
-
Franco Moretti, Graphs, Maps, Trees: Abstract Models for Literary History (London: Verso, 2007); Moretti, Distant Reading (London: Verso, 2013); Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History (Urbana: University of Illinois Press, 2013). ↩
-
Maxim Romanov, ‘Algorithmic Analysis of Medieval Arabic Biographical Collections’, Speculum 92, no. S1 (October 2, 2017), S226–46, doi:10.1086/693970. ↩
-
Maxim Romanov and Masoumeh Seydi, ‘Al-Ṯurayya, the Gazetteer and the Geospatial Model of the Early Islamic World’, in Digital Humanities 2019 Conference Papers (9–12 July 2019), Utrecht University, 2019, clariah.nl/files/dh2019/boa/0909.html. ↩
-
Georgette Cornu, Atlas du monde arabo-islamique à l’époque classique: IXe–Xe siècles (Leiden: E. J. Brill, 1985). ↩