

Data annotation and evaluation is a critical part of the KITAB-Transform workflow. Without user-friendly but highly customisable software, it will be impossible to collect the quantity of data that we will need to achieve of goals. This is our first blog post introducing the annotation workflow and software that we will be adopting in the project. It is intended as an introduction and will likely be followed by a number of posts addressing specific annotation tasks or the details of the workflow and possibly some more technical descriptions. Here we will stick to the basics, but we hope the post will convey some of the possibilities.
In the KITAB-Transform project, we’re training language models to identify “transformative” text reuse (such as paraphrase and translation) in the OpenITI corpus. In order to train these models, we need training data: samples of pairs of passages that contain (or don’t contain) paraphrase and translation, accompanied by labels that describe the relationship between them. These labels can, for example, indicate whether a pair of passages is an example of a specific transformation (“paraphrase”, “translation”), so that the model can learn to distinguish these categories:
{
"A": "This is a simple example",
"B": "هذا مثال بسيط",
"category": "translation"
}
Alternatively, labels can indicate where exactly in a pair of longer passages the reuse instances are located:
{
"A": "This is a more complicated example, embedded in some context",
"B": "هذا مثال أكثر تعقيدًا والنصف الثاني غير مرتبط",
"labels": \[
{
"category": "translation",
"A\_span": \[0, 34\],
"B\_span": \[0, 21\]
}
\]
}
(in this example, only the first part of each passage corresponds to a translation: the first 34 characters of passage A and the first 21 characters of passage B).
Such labeled data can be used to train a model to detect or classify forms of text reuse. Once we have trained a model, we need a separate set of passage pairs which the model hasn’t seen during its training (evaluation data), to check how well it is performing on data it has not encountered before. We can also use this evaluation data to test the performance of existing models if they are available.
LabelStudio
To generate these training and evaluation datasets, we have been experimenting with a piece of open source software called LabelStudio.
LabelStudio is designed for generating training data for AI models and can handle text, images, video, audio and other data types. It has a flexible interface that (supposedly) can be adapted to any task.
We are planning to use LabelStudio for a number of different tasks:
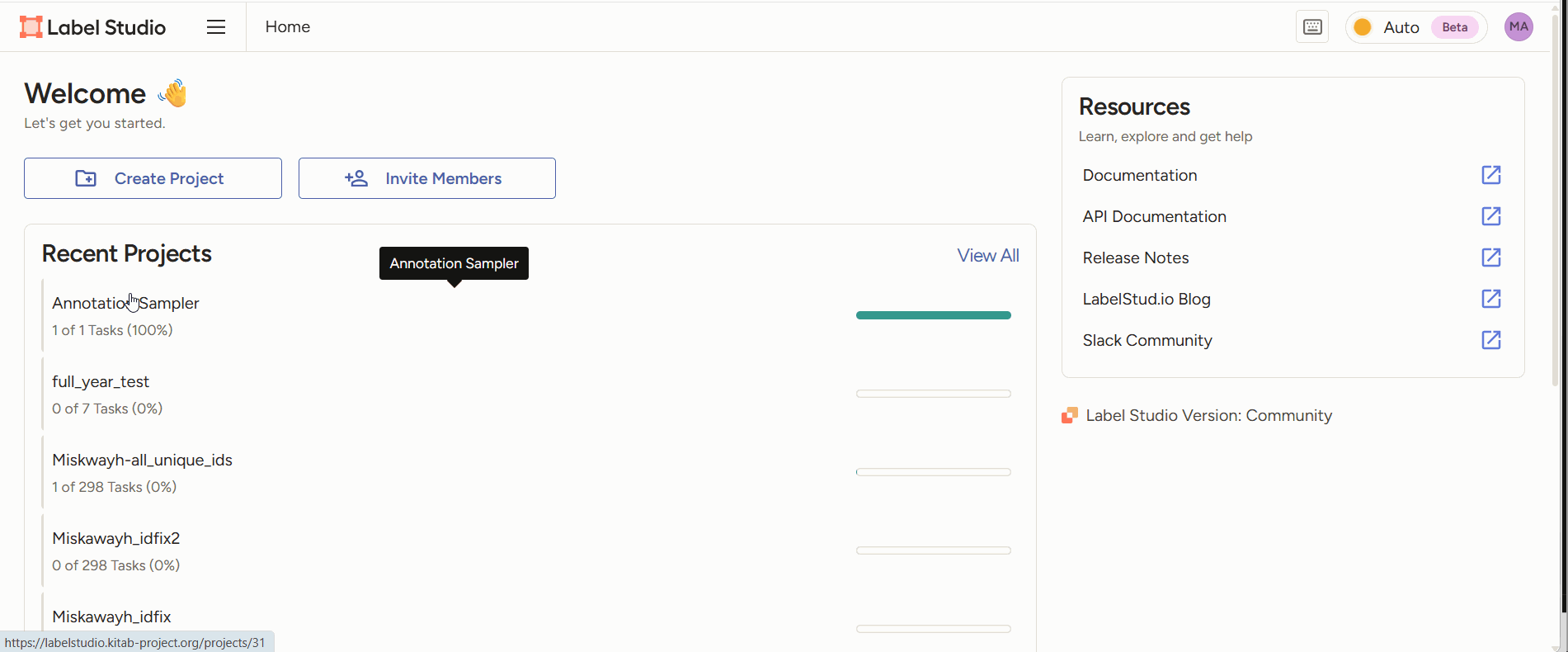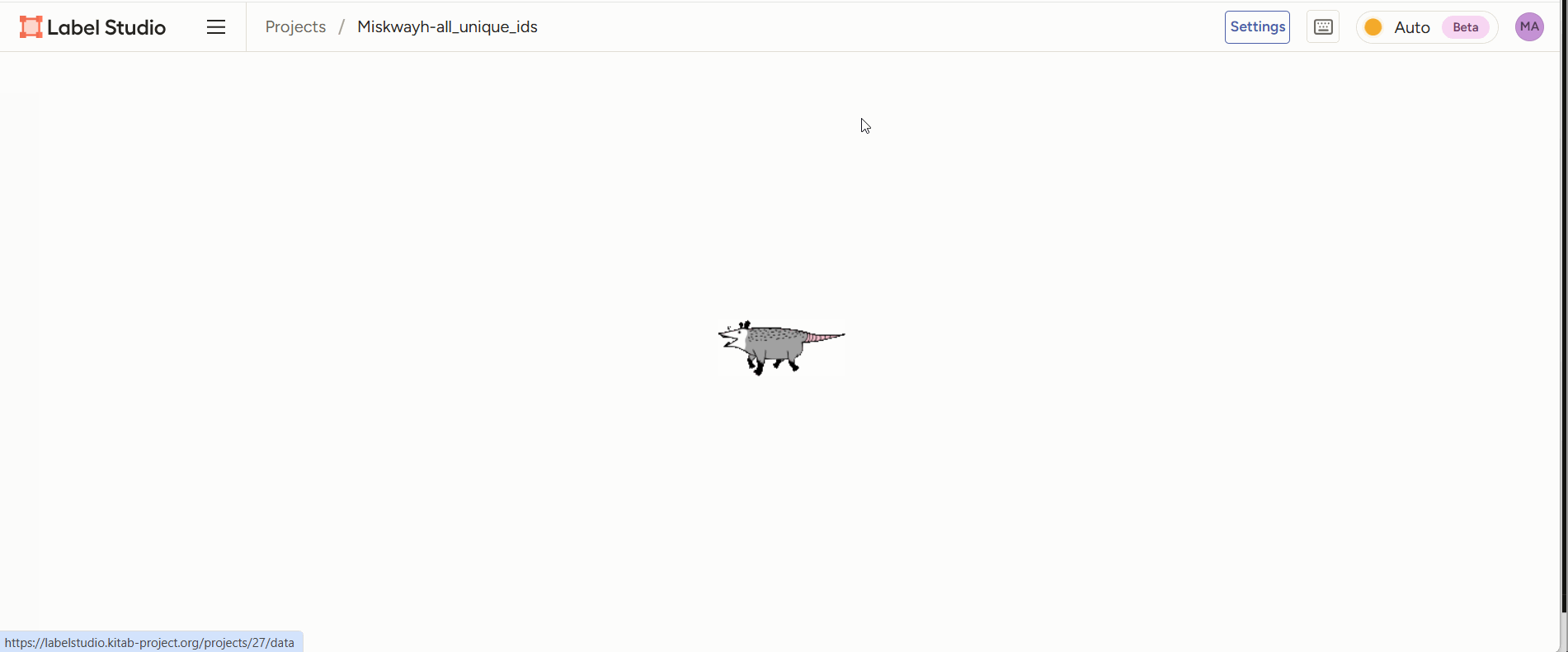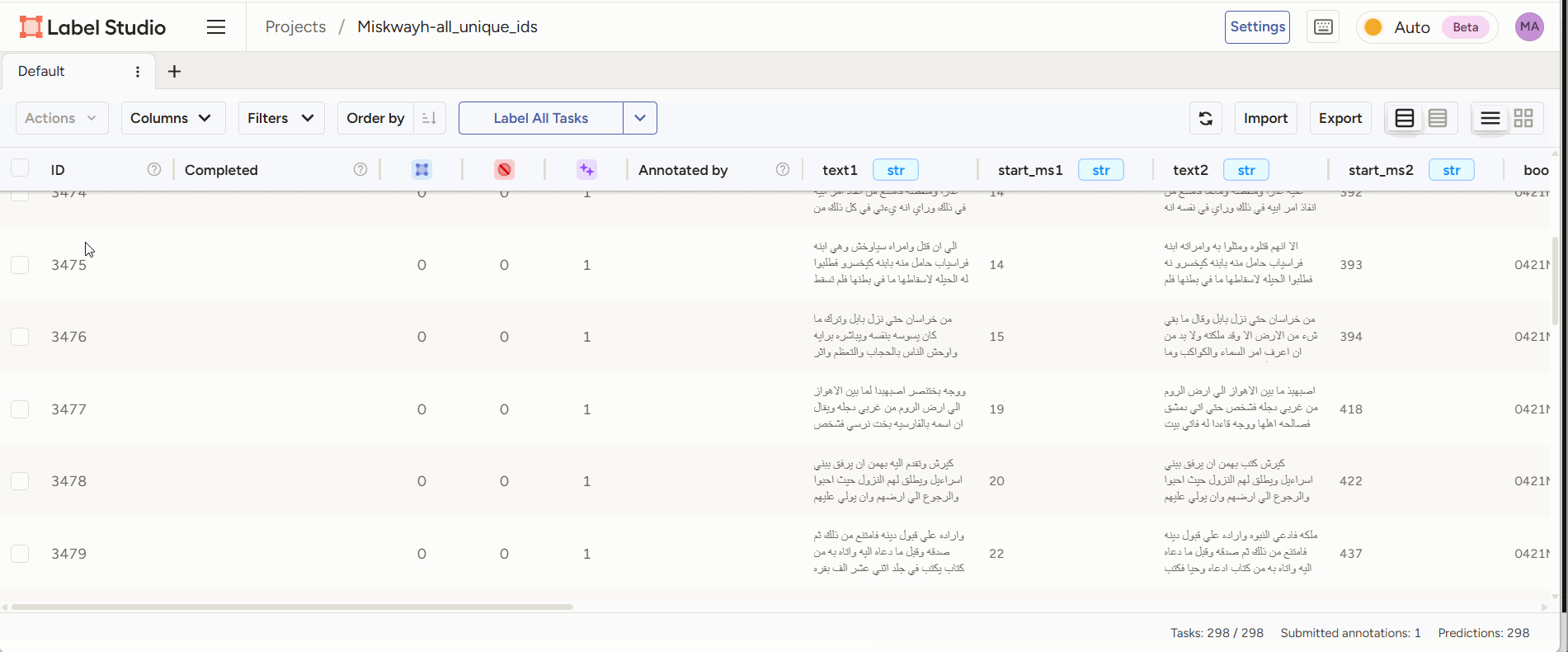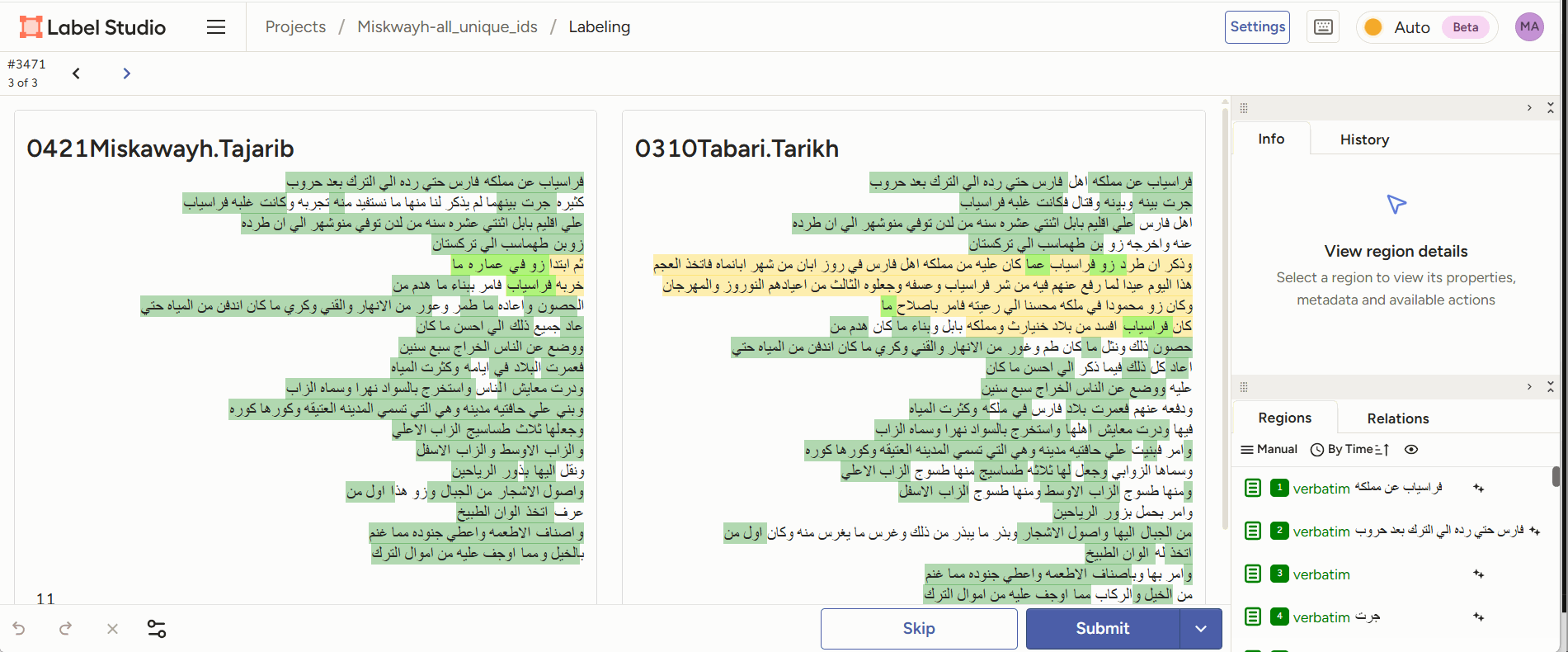
- Span annotation: given two pieces of text, highlight reuse passages between the two.
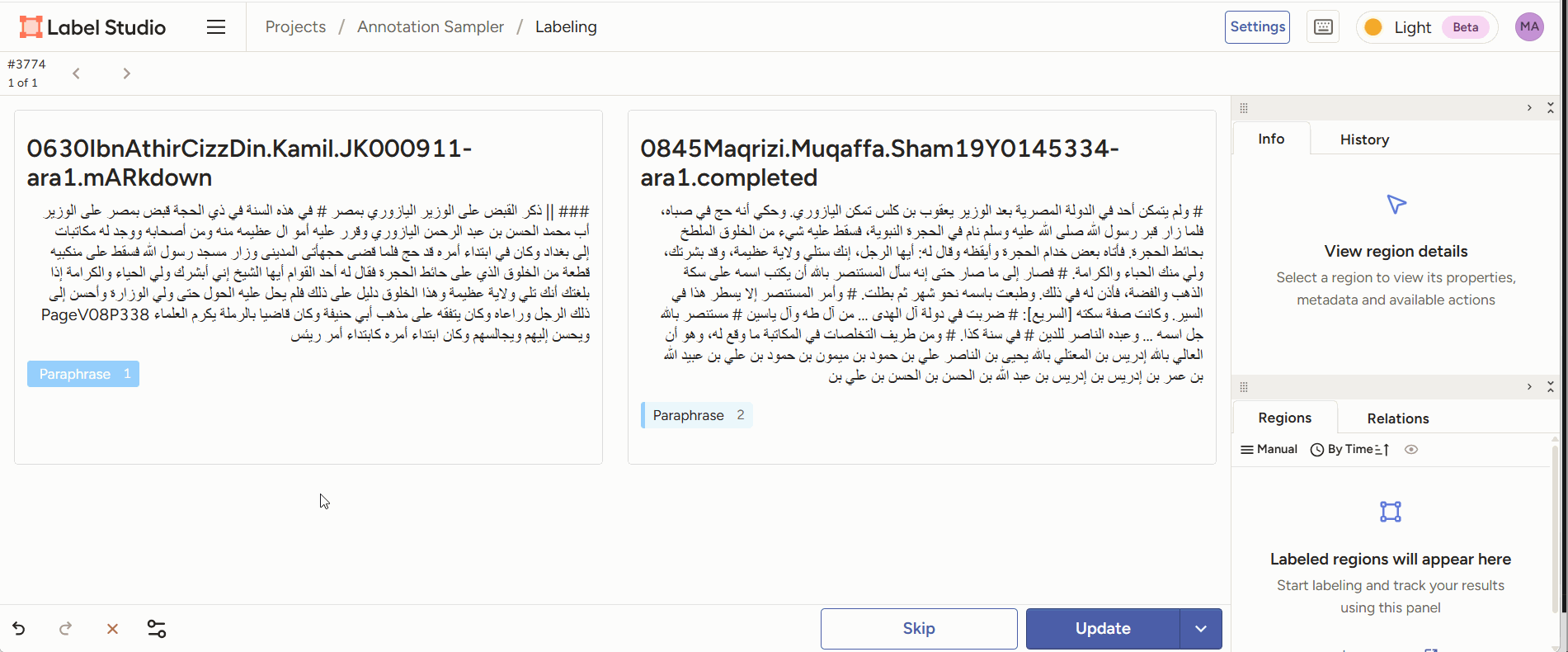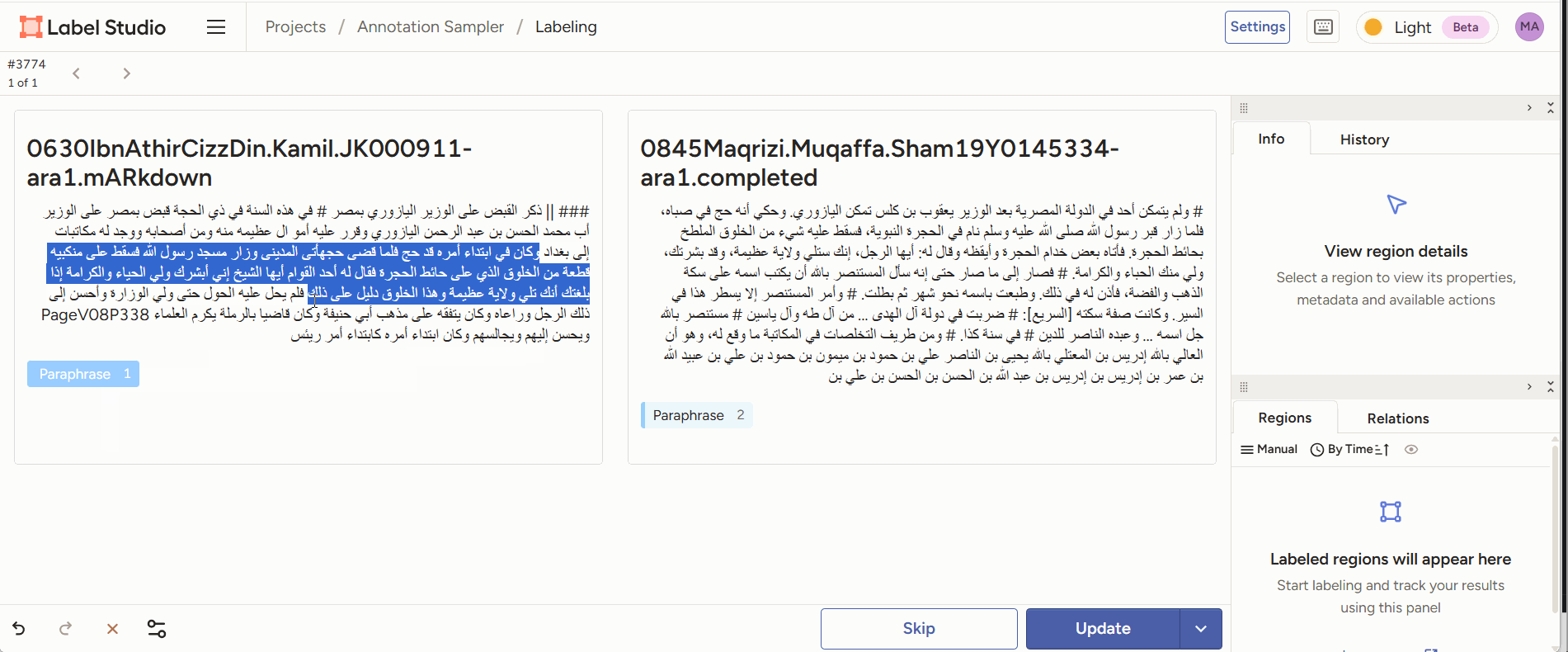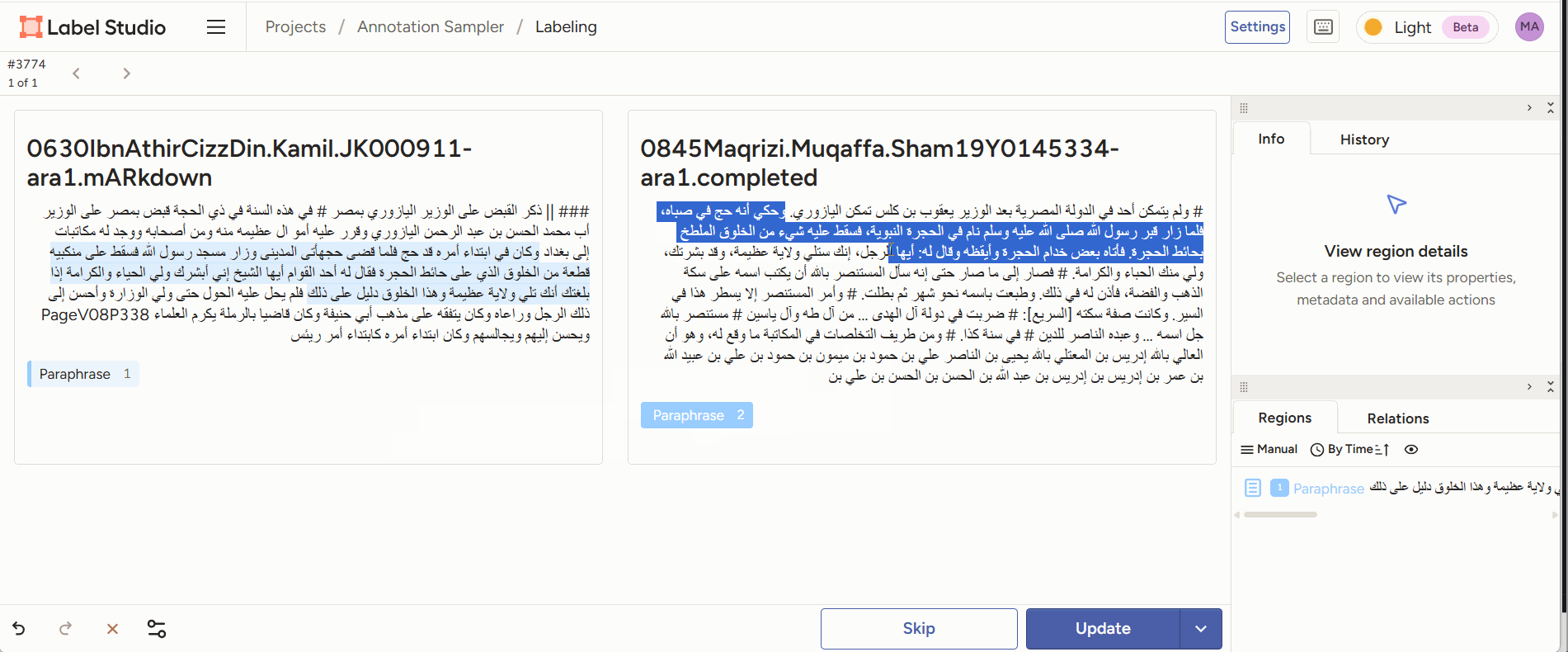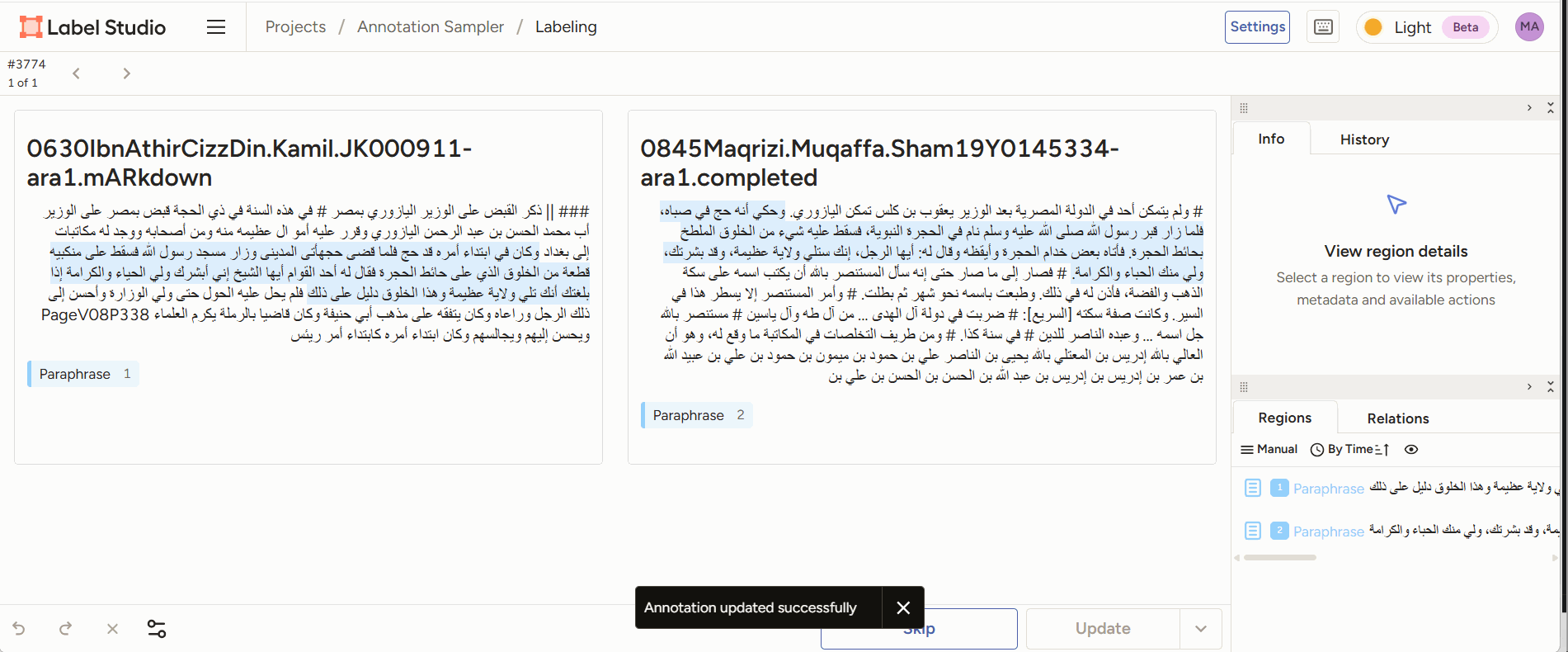
Figure 2: annotators read two juxtaposed text sections and mark the parts they consider paraphrase. - Classification: given two reuse passages, classify the type of reuse.
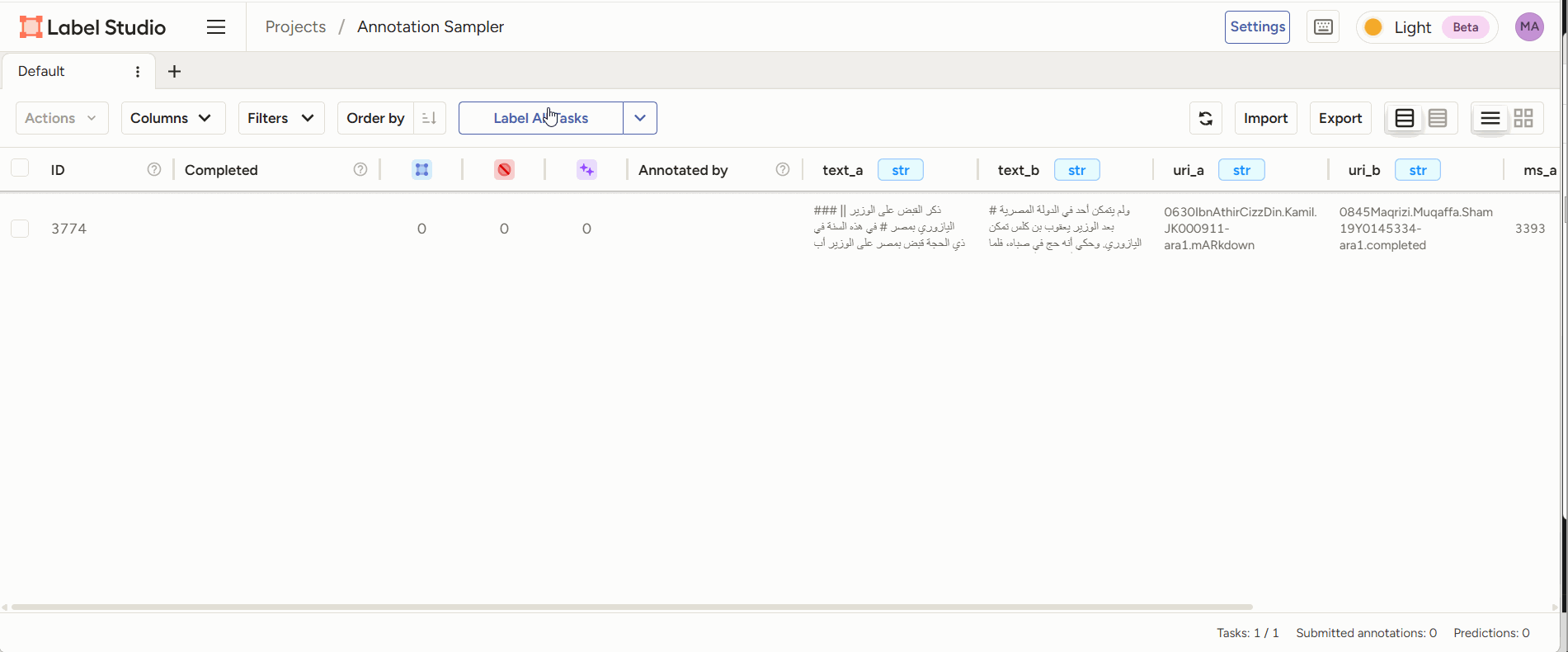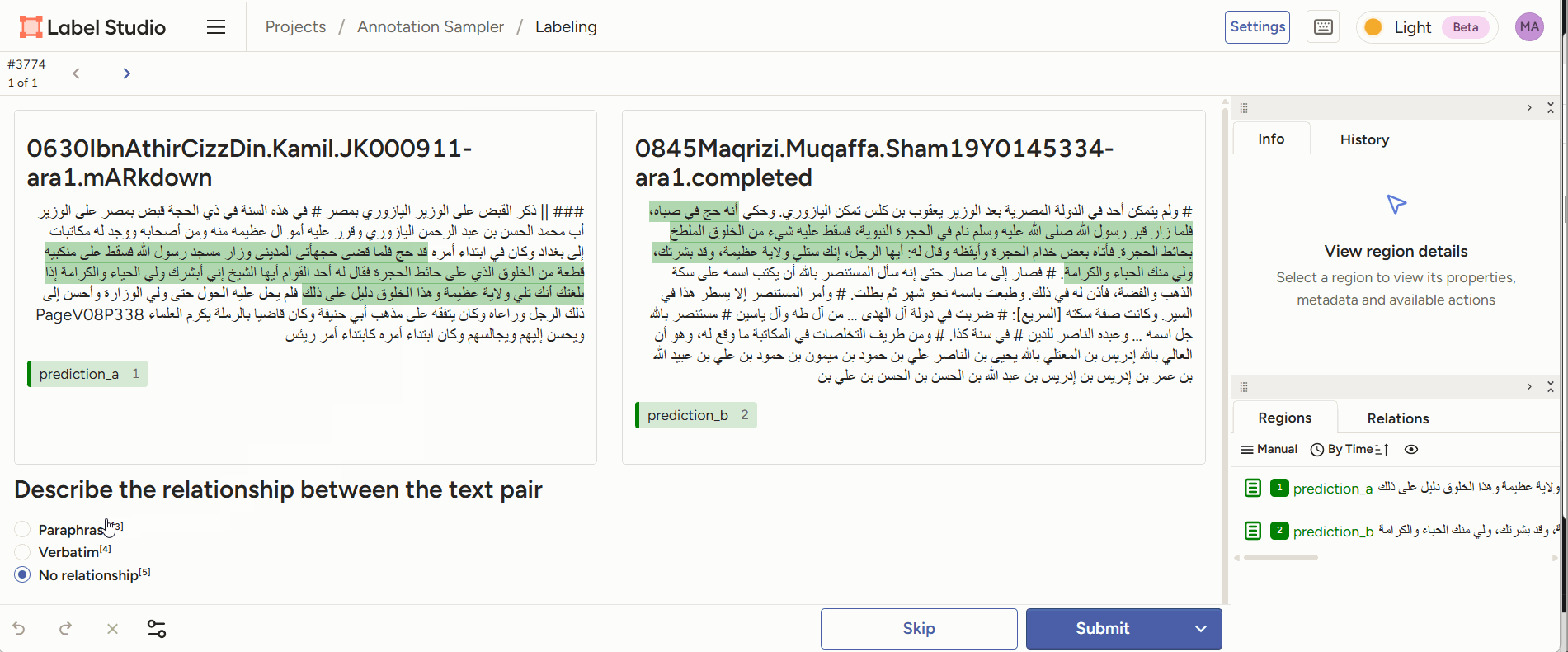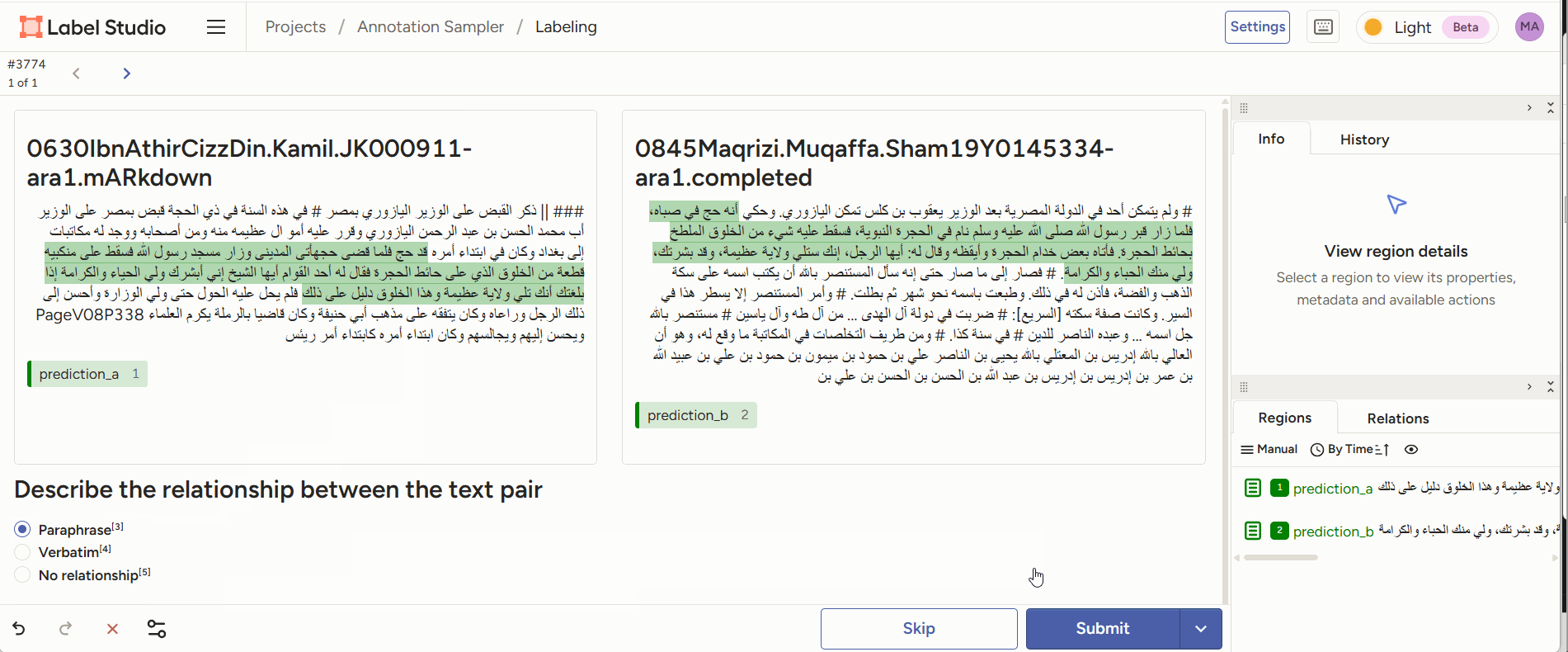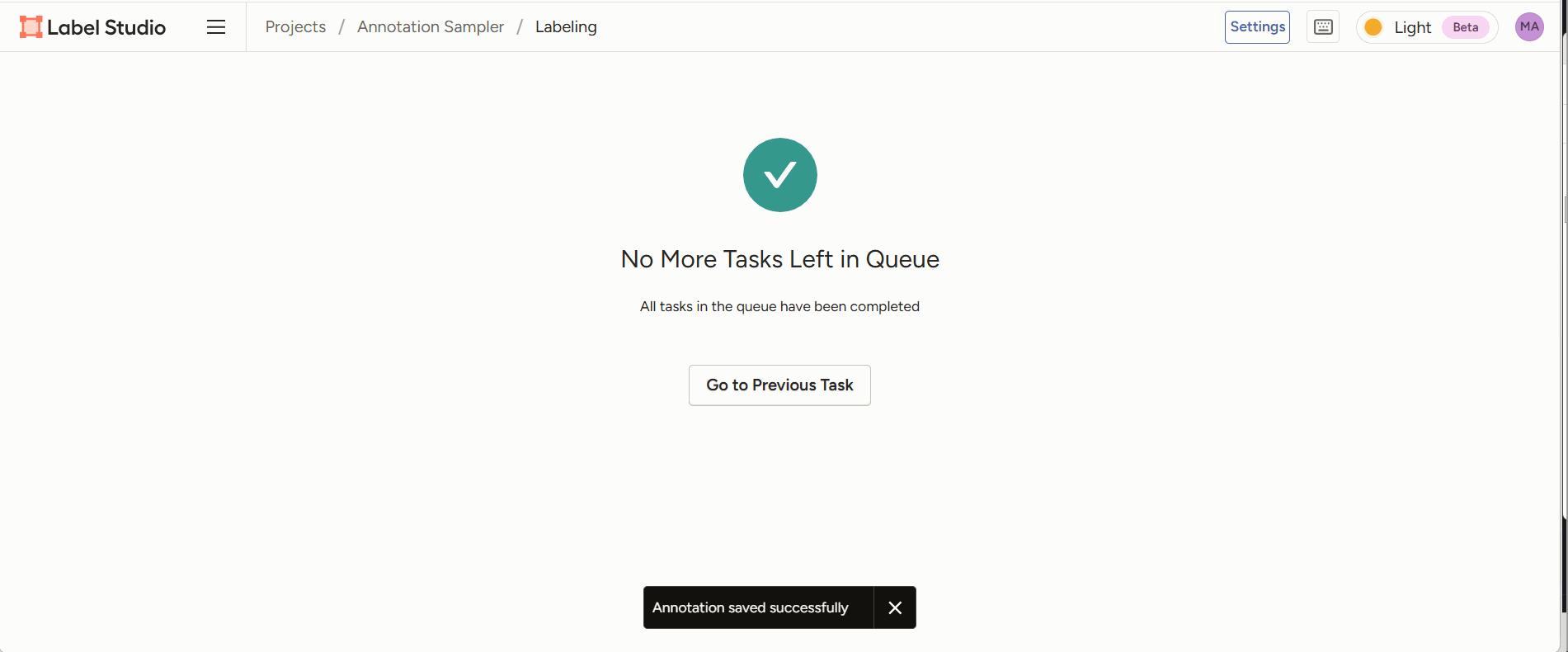
Figure 3: annotators are given two pieces of text of which a part is highlighted. The annotator’s task is to decide which form of paraphrase this is an example of. - Evaluation: given the output generated by a model (e.g., a classification of two passages as a case of paraphrase), a human annotator can score or correct the model’s judgment, or adjust/correct the boundaries of the identified passages.
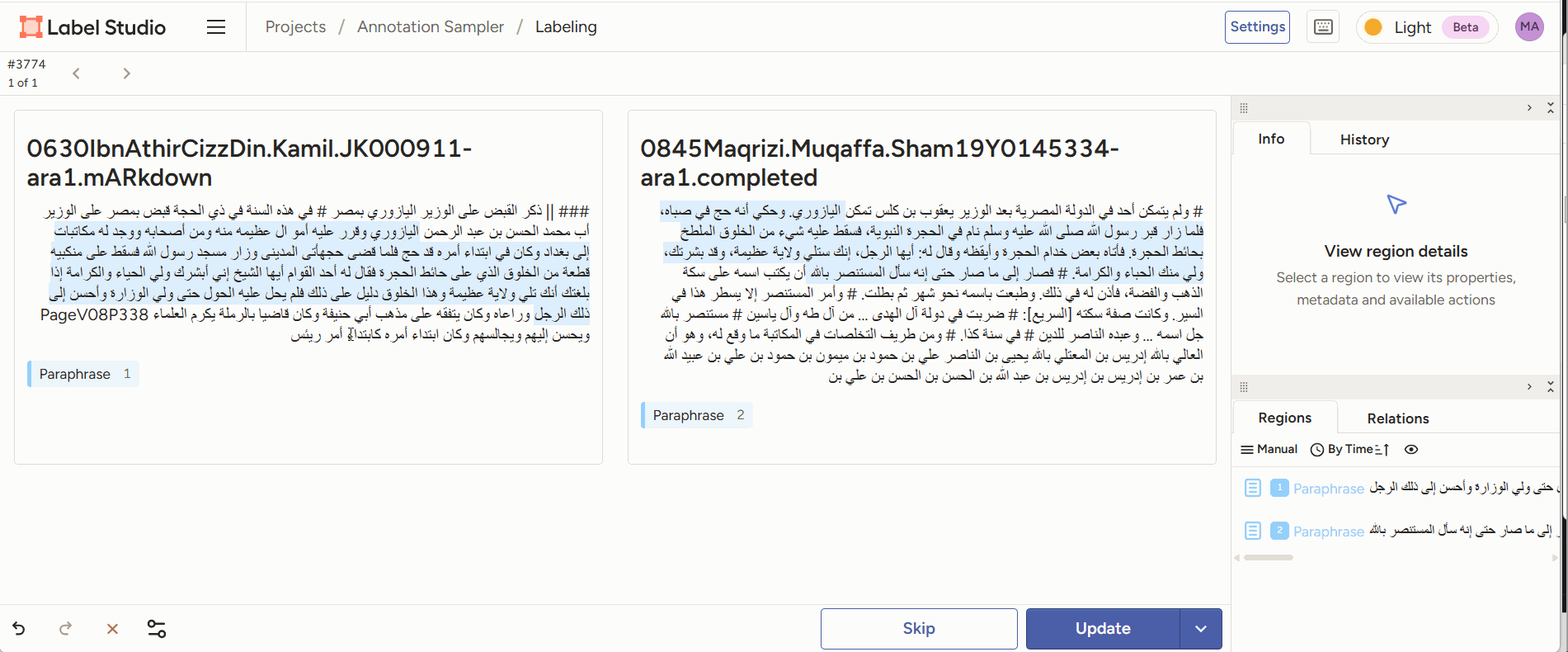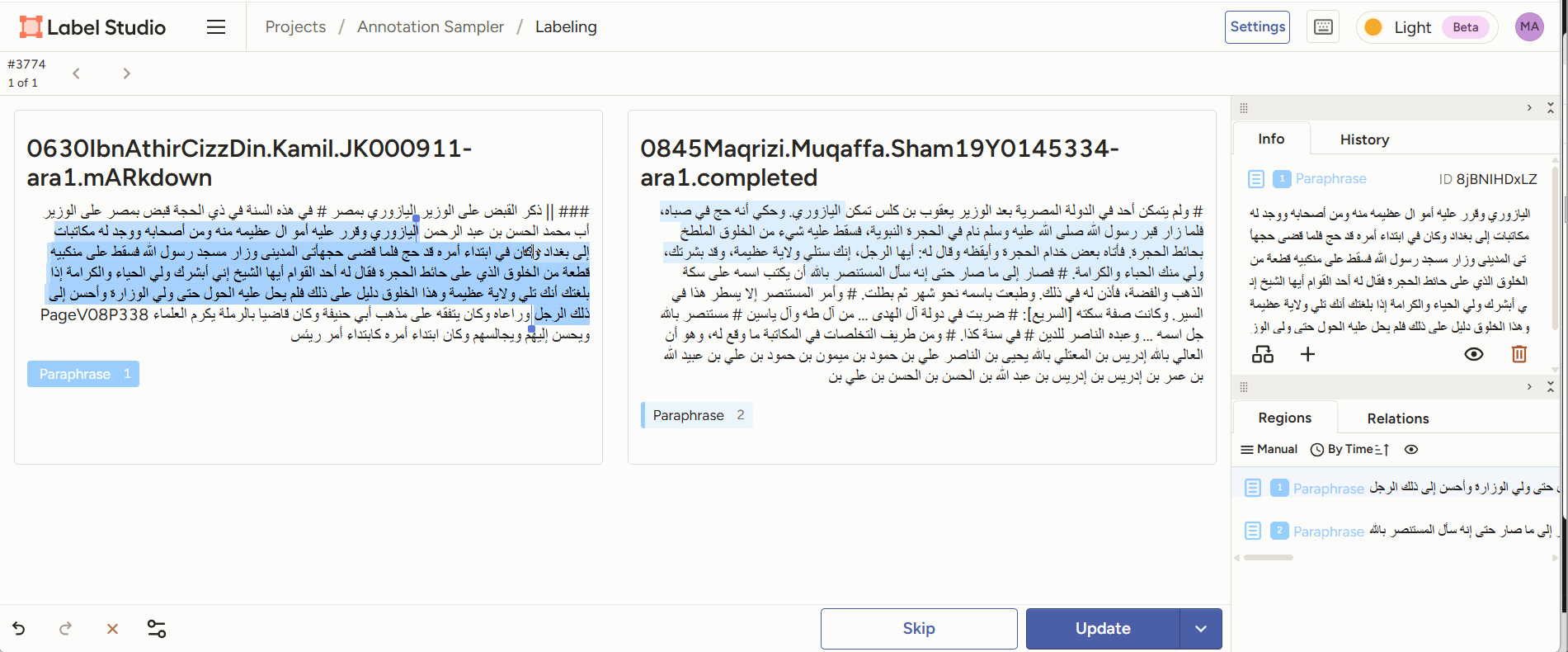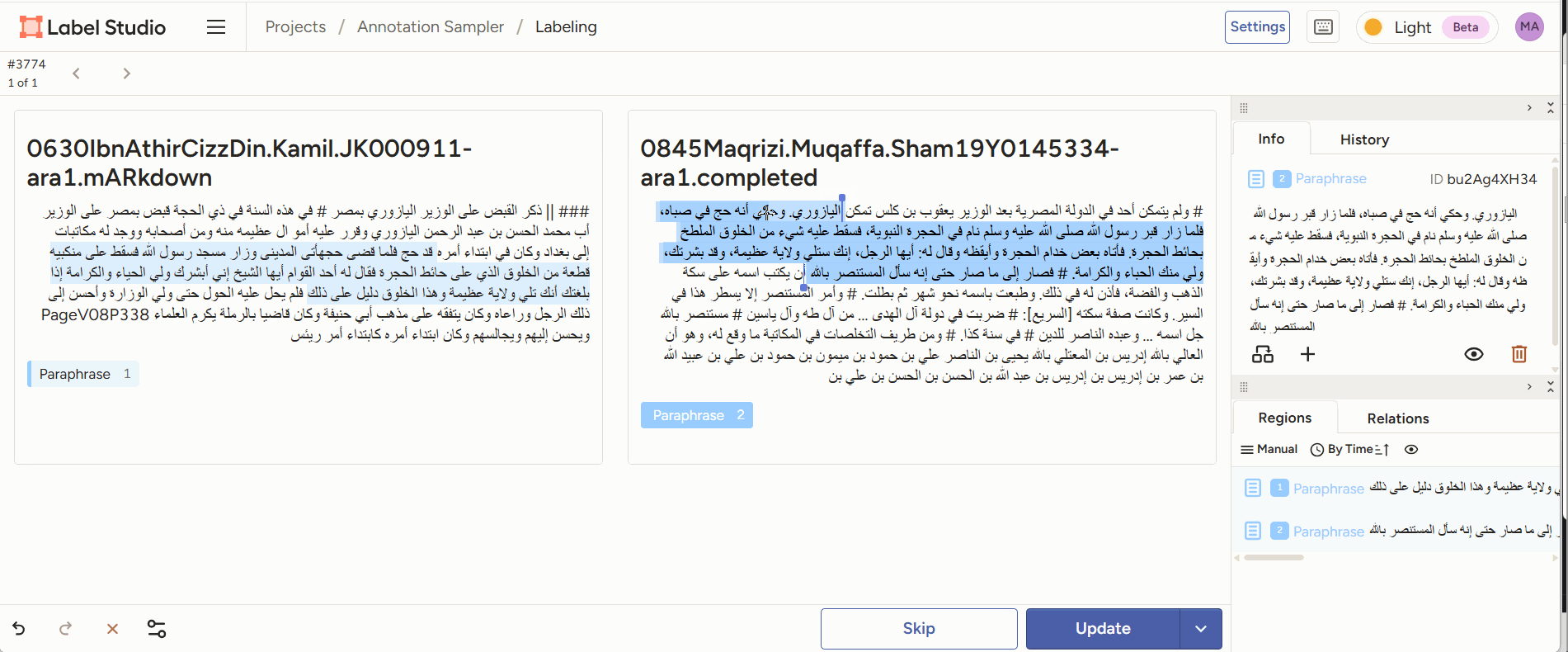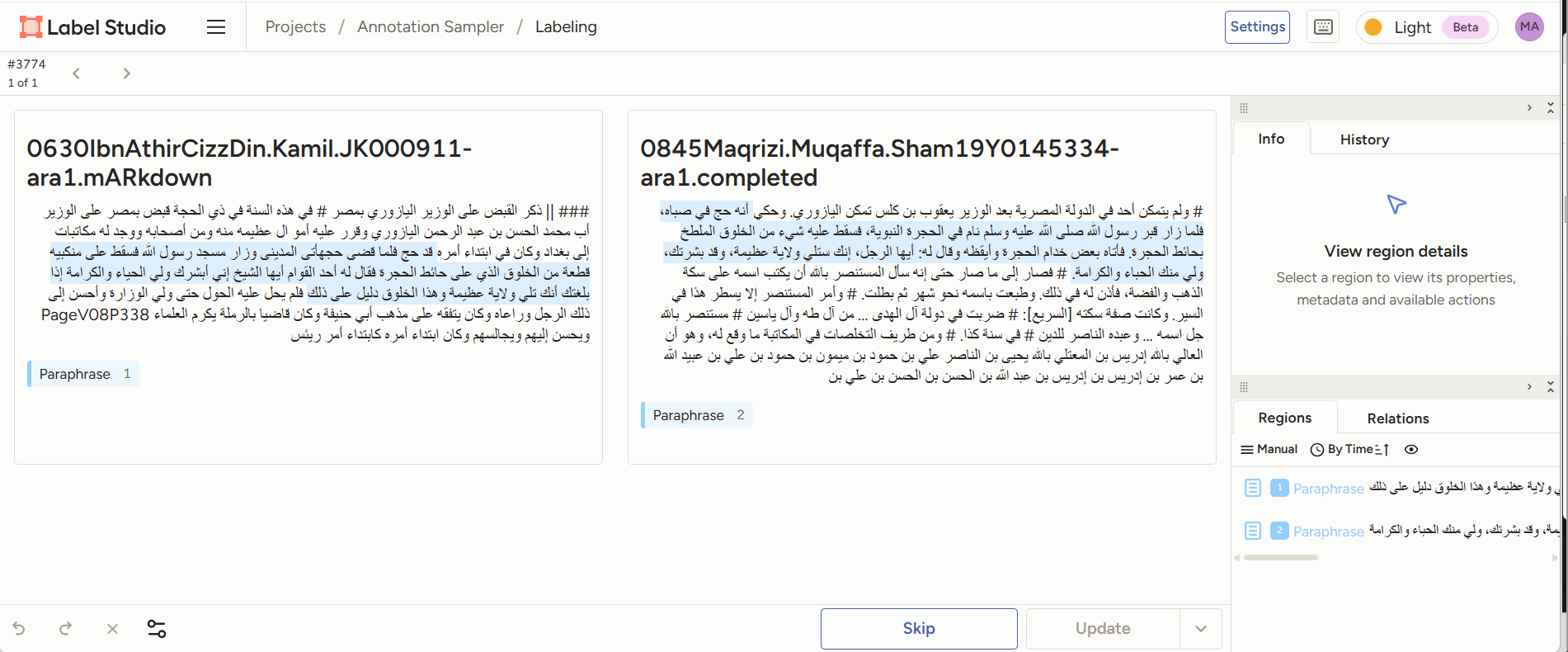
Figure 4: Annotators are given two pieces of text of which a part is identified as paraphrase by a model. They can correct the start and end point of the paraphrase sections, and add comments. - inter-annotator agreement study: multiple human scholars annotate the same passage pairs and we compare their decisions. How much humans disagree is a good measure of how difficult a task is for a computer. LabelStudio allows us to do this out-of-the-box by sharing an annotation task with multiple different annotators.
We are currently self-hosting the free version of LabelStudio on a cloud server; there is also a paid version of the software, which is hosted on their servers, and with more options for project management.
How do we find passages to compare in LabelStudio in the first place?
We have a number of strategies:
- We start from pairs of texts of which we know that one is (partially) a paraphrase / summary / versification / translation of the other. For example, Sarah Savant is looking at Miskawayh’s Tajarib al-umam (Experiences of the Nations), which paraphrases much of al-Tabari’s Tarikh (History); and Lorenz Nigst is comparing Ibn Ata Allah al-Sikandari’s Hikam (Aphorisms) with a versification ascribed to Radi al-Din al-Ghazzi.
- We use the text reuse data generated by passim in the first phase of our project to identify passages sandwiched between two sections of verbatim text reuse in a pair of texts. The idea is that it is likely that such gaps between near-verbatim text reuse sections contain examples of paraphrase, which passim was not designed to detect.
- We use structural annotation in OpenITI texts to align passages that are likely to contain the same content and possibly paraphrase one another. For example, compare sections related to the same year for different chronicles. To identify the years, automatic tagging might be utilised, relying on regular expressions.
In the next blog post we will explore one of these strategies in further detail and explain how we are preparing and importing data into LabelStudio.