Stylometry, or the computational analysis of writing style, is based on the premise that each author has a unique way of writing, which can be quantified in the form of word frequencies and measured against texts by other authors. As such, stylometry can enhance traditional ‘close reading’ by focusing on one or several texts, and ‘distant reading’ approaches by analysing and visualising enormous corpora at once for macroanalysis. In literary history, stylometry is most used for authorship attribution and genre detection. This makes it a relevant and attractive method for the study of textual heritage in Arabic and Persian. It must be said that most of the methods and tools currently available are designed for and trained on Western languages and literatures. At KITAB we are interested in adapting methods and techniques of stylometry to the study of Arabic texts, which by virtue of their intertextuality present different types of challenges from those posed by texts in European languages, but also exciting opportunities for researchers. With every OpenITI corpus release we also prepare a parallel corpus specially pre-processed for use with the stylometric program R stylo.
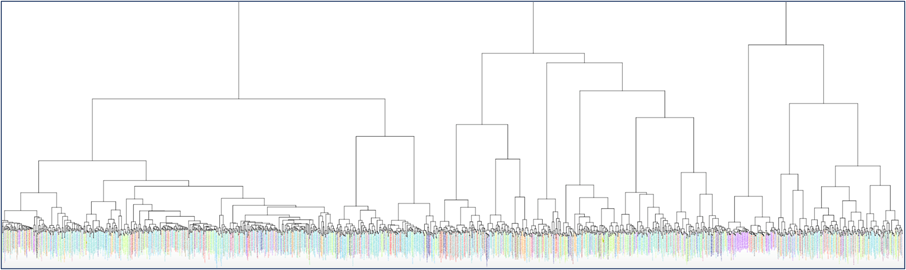
Figure 1: Cluster analysis of about 2,000 texts from the first five hundred years of the Arabic book (1/622–505/1111 CE).
Networks from Stylo results
Thematic and stylistic relationships between texts in a corpus can be viewed as a network in which the strength of a relationship is determined by the distance between the two works. In other words, we can conceive of the corpus as a network in which all texts are related to each other with varying degrees of closeness. Individual books are nodes, and the distances between them are the edges (links). We can gauge the degree of similarity and influence between the texts by how close to each other they are in the network. The R stylo program produces a table of links between the books in the corpus, and this can then be fed into a network analysis software such as Gephi or other network analysis packages.

Figure 2: A network based on the stylometric distances between books in the corpus derived from five hundred years of the Arabic written tradition.