
Due to its size and coverage, the OpenITI corpus is useful for a wide variety of research purposes. In particular, it represents an excellent opportunity to apply computational methods from natural language processing and machine learning to solve problems of interest not only to historians but also to computer scientists. This post will focus on one specific problem – that of detecting embedded genres in texts in the OpenITI corpus. Embedded genres are portions of a larger work that can be thought of as belonging to a genre distinct from that of the work itself, such as poetry embedded in a historical narrative or chains of transmitters (isnads) embedded in a discussion of grammar. This phenomenon is found throughout the corpus.
As a case study, we will focus on detecting isnads: we will give an overview of machine learning and of the process used to create the training data and models for automatic identification of isnads in the corpus. Unlike prior work on automatic Hadith tagging, this work focuses exclusively on trying to identify isnads, without also trying to simultaneously extract the corresponding reports (matns) for each chain or to extract information from the identified isnads, as others have done.1 Additionally, we are working with a much larger and correspondingly more diverse collection of texts. Furthermore, much of the existing work, like the studies cited above, focuses on using rule-based systems to identify isnads and the individual transmitters within them, which limits the generalisability of these models to previously unseen texts.
The task of identifying isnads in the corpus has interesting future applications, both historiographically and technically. For historians, even something as simple as the ability to identify where isnads occur allows one to, for example, track how the importance of certain texts changes over time based on what gets cited and how, or understand the relative importance of Hadith citations in different texts.
Computationally, our research on isnads has myriad applications to other problems in natural language processing. It lays the groundwork for improving the models used to track text reuse in the corpus, as isnads currently indicate a great deal of similarity and reuse that is statistically meaningless. Additionally, it allows one to look at the problem of converting the text of an isnad into a network of relationships among the mentioned transmitters using the isnads found with this model as training data. Then, rather than having, say, a piece of text which states that Ibn Saʿd heard some information from Ibn Ishaq, the computer would know that there are two people, one called Ibn Saʿd and the other called Ibn Ishaq, and that the former received information from the latter. This would, in turn, allow scholars to apply methods from social network analysis to understand how texts were compiled and transmitted by exploring how different people participated in the dissemination of knowledge. Similarly, it creates a wealth of training data for named-entity tagging in classical Arabic texts, as isnads are innately name-rich. This will allow later research to leverage the output of this model as a way of improving the performance of models designed to locate the names of people in a text using the names present in isnads as additional training data.
Having discussed why this task is useful to undertake, we will turn our attention to how exactly we can go about performing it on a collection of texts on the scale of our corpus, with about 4,200 unique texts totalling more than 1.5 billion words. In order to underscore the iterative nature of this sort of work, we will present two different approaches to the task of isnad detection. Both approaches involve building mathematical models of what isnads look like using a set of examples created by human annotators. These models can then be used to find other isnads in texts which the model has never seen before. This is an example of a ‘supervised problem’, where the model learns from training data, which consists of examples of what it is trying to find – in this case isnads – and examples of what not to look for. (For an example of an unsupervised problem, such as text reuse detection, see the discussion in previous blog posts.) The exact form of the training data can vary depending on how the models work.
The first approach relies on the idea that isnads display a characteristic distribution of particular words, including ‘transmissive terms’ such as haddathana and qala and common name elements such as ibn that can be used to identify what parts of a text are likely to be isnads. Since in other contexts these terms will have a different distribution, looking for regions of text which use language similar to that of known isnads will be enough to reliably identify them. This is done by building two language models, which are trained on different kinds of text: one is trained on examples of isnads and another is trained on examples of text which are not isnads (the latter is called the ‘background’). Examples of the training data for the isnad model can be seen in Figure 1 below. The data consists solely of a collection of isnads provided by human annotators. The background model is trained on the entire corpus.

Figure 1: Training data for the isnad model.
These models can be used to quantify the likelihood that some piece of text is an isnad or is not an isnad, respectively. Text that looks more similar to the training data used for a model will receive a higher likelihood under that model. Using these two models, we can figure out the best way to divide a new text into sections, some of which are isnads and some of which are not, effectively breaking the text into a series of labelled sections of words. For example, if a certain portion of the text looks similar to the isnads which were used as training data for the model, it will be labelled as an isnad, since it is more likely to be one under the isnad model. In contrast, portions of the text that look similar to the background will be labelled as not an isnad, since they are more likely not to be isnads under the background language model.
As sensible as this approach sounds, it actually performs quite poorly since it is not very sensitive to the different contexts in which words can appear and how those affect their meaning. For instance, qala (‘he said’) can be used both as a transmissive term within an isnad and as a way of introducing quotations. This model isn’t capable of distinguishing between those two situations easily.
To address these issues, we decided that instead of trying to tag entire spans of words as isnad or not, we would instead tag individual words as part of an isnad or not on the basis of other words that surround them within some fixed window. Using this alternative method, we would be able to give the model a more nuanced understanding of context and its effect on what the correct labels for the words should be. This process, unfortunately, involves much more labour-intensive manual annotation of texts to insert isnad markers, as in Figure 2 below. @Isnad_Beg@ marks the beginning of an isnad, while @Isnad_End@ marks its end.

Figure 2: Manually annotated text with isnad markers used to train the word-tagging model. @Isnad_Beg@ marks the beginning of an isnad, while @Isnad_End@ concludes it.
This text is then converted into a list of words and the correct tags associated with them, as in Figure 3. Words at the beginning of isnads are tagged as ‘B_Isnad’, while those that are inside isnads are tagged as ‘I_Isnad’. Finally, although this is not visible in the example tags below, words that are not part of an isnad receive the tag ‘O’ (‘Outside’). This data is then used to train the model by associating some information with each word – both about the word itself and about the frequencies of words used before and after it, within some fixed window. Computer scientists call this process ‘featurisation’. For example, an early passage from Ibn Qutayba’s Gharib al-hadith is tagged and featurised as in Figure 3.
قال أخبرنا أبو محمد عبد الله بن مسلم بن قتيبة
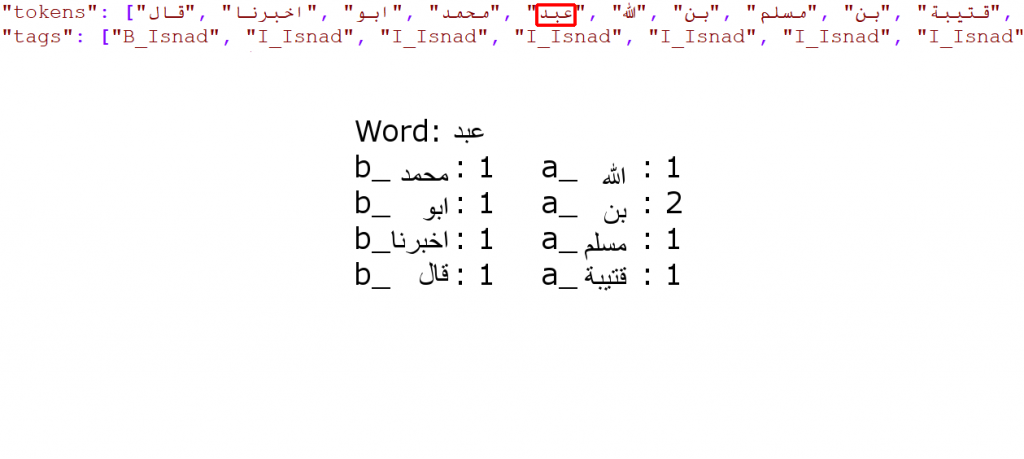
Figure 3: An example of tagged text and featurization with a window size of five words. Note that ‘بن’ occurs twice after the current word within the window, and that is reflected in the value for the ‘a_بن’ feature.
During training, the model will then use this representation of the text to learn to interpret things like the presence of a high number of transmissive terms or names in the text around a word as an indicator that it is part of an isnad. Unlike the first approach, this model also has the ability to take context into account when the surrounding text doesn’t look like an isnad, and label the text accordingly. This will reduce false positive matches, such as when qala is used to introduce quotations of written text. Once trained, the model can be used to label isnads in new texts by inferring the most likely tags for that new text. To do this, the text is featurised as described above and the trained model is used to find the most likely tag sequence (labelling of words as part of an isnad or not) for that featurised data.
To evaluate the model, we performed a process called tenfold cross-validation. First, the data is divided into ten pieces, called folds; second, a model is trained on nine of the folds; third, the trained model is tested on the remaining tenth fold; and fourth, the process is repeated nine more times until each fold has been used as test data. This results in ten trained models and ten sets of scores, which are then averaged – as shown in Table 1 below.
| Precision | Recall | F1 |
|---|---|---|
| .853 | .805 | .819 |
Table 1: Evaluation statistics for the word tagging model.
Precision and recall are two similar metrics used to measure the performance of machine-learning algorithms, with a critical difference. Precision measures the percentage of words that the model tagged as part of an isnad that actually are part of isnads. Recall, in contrast, measures the percentage of words that should be labelled as part of an isnad that the model in fact labelled as such.
To give a concrete explanation of what these measures mean, a model with high precision but low recall would tend to label few words as part of an isnad, but those that it did would usually be correctly labelled. Conversely, a high-recall, low-precision model would label many words as belonging to isnads, finding most of the words it ought to but also labelling many words erroneously . F1 is used to summarise precision and recall in a single value. We cannot, unfortunately, say how this compares to human results on the isnad detection task, as we don’t have any data on how difficult the task is for humans.
As a further experiment, we tagged the entirety of Ibn ʿAsakir’s (d. 571/1176) Taʾrikh madinat Dimashq (800,000 words in total) and found that, according to our model, it contains just under 91,000 isnads, comprising about 40% of the text.
This work would have been impossible without close collaboration between myself and other members of the KITAB team. In particular, Professor Sarah Savant, Professor Kevin Jaques, research assistant Mathew Barber and PhD student Hassan Ahmed provided vital training data for the models discussed above.
-
For the former, see Fouzi Harrag, ‘Text Mining Approach for Knowledge Extraction in Sahîh al-Bukhari’, Computers in Human Behavior 30 (2014), 558–66; Hajer Maraoui, Kais Haddar and Laurent Romary, ‘Segmentation Tool for Hadith Corpus to Generate TEI Encoding’, in International Conference on Advanced Intelligent Systems and Informatics (Cham, Switzerland: Springer, 2018), 252–60; Shatha Altammami, Eric Atwell and Ammar Alsalka, ‘Text Segmentation Using N-grams to Annotate Hadith Corpus’, in Proceedings of the 3rd Workshop on Arabic Corpus Linguistics (n.p.: Association for Computational Linguistics, 2019), 31–9. For the latter, see Muazzam Siddiqui, Mostafa Saleh and Ahmed Bagais, ‘Extraction and Visualization of the Chain of Narrators from Hadiths Using Named Entity Recognition and Classification’, International Journal of Computational Linguistics Research 5/1 (2014), 14–25. ↩