
One of the participants in our KITAB user group asked for an easy way to find out which are the most frequently used words in a text.
There are quite a lot of online tools that allow you to upload a file (or provide a link to a web page) and will produce a nice table with word counts.
Unfortunately, this specific user group participant works with the largest text in the KITAB corpus, Ibn al-ʿAsakir’s Taʾrikh madinat Dimashq, which weighs in at about 75 MB in the OpenITI version, and none of the sites I tried out was willing to accept such a large file. Others failed to produce a frequency list even with smaller books, probably because they don’t deal well with Arabic.
There are a number of other options to create frequency lists from a text, but most involve using a programming language such as Python or R. Since most of our user group participants do not have any background in programming, we thought about using this question as an opportunity to show the user group how to install Python or R and run a simple script to create the frequency list (for example, using the fantastic R stylo library).
However, even demonstrating something simple like this to people who do not have Python or R installed and are working on different platforms always takes quite some time, time we didn’t have during our user group meeting.
So, after getting frustrated with a number of websites that promise to convert a text into a frequency list, I decided to build such an online tool for OpenITI myself.
This was quite straightforward because I could build on work we have done for our OpenITI Python library and other subprojects.
The tool can be found here.
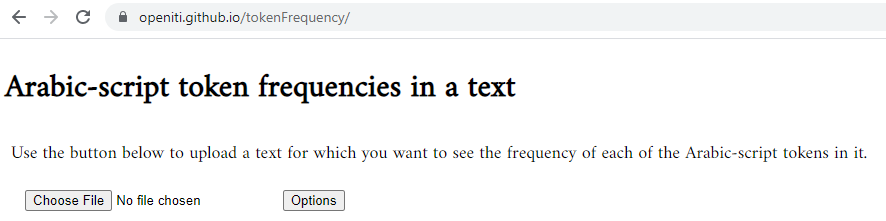
In its simplest form, you upload a text and get a table with token frequency counts in return. You can browse through the table online or download it as a csv file (by clicking ‘Download table as csv file’ at the top of the table) that you can import into a spreadsheet program.

An additional advantage of building such a tool yourself is that you can customise it to your own wishes. I added a number of options I would personally find useful:
-
a minimum limit for the number of times a token needs to be in the text for it to be included in the table
-
a list of ‘stop words’ – that is, tokens to be excluded from the count
-
an option to define what the tool must consider a token. By default, it considers any sequence of Arabic-script characters a token (see below for a full list of these characters). You can also provide your own definition of what characters should be considered a token by providing a regular expression of your own. (Note for those who know about this type of stuff: Javascript’s regular-expression engine is used for the tokenisation, so
MARKDOWN_HASHa9611d04392ad1acb0cd7642a0e405dfMARKDOWN_HASHrefers only to ASCII word characters.) -
an option to split off a metadata header, so that words that are not really part of the text are not counted in. By default, the OpenITI metadata header is split off from the main body of the text, but you can also provide a regular expression of your own to split off headers that are delimited in another way.
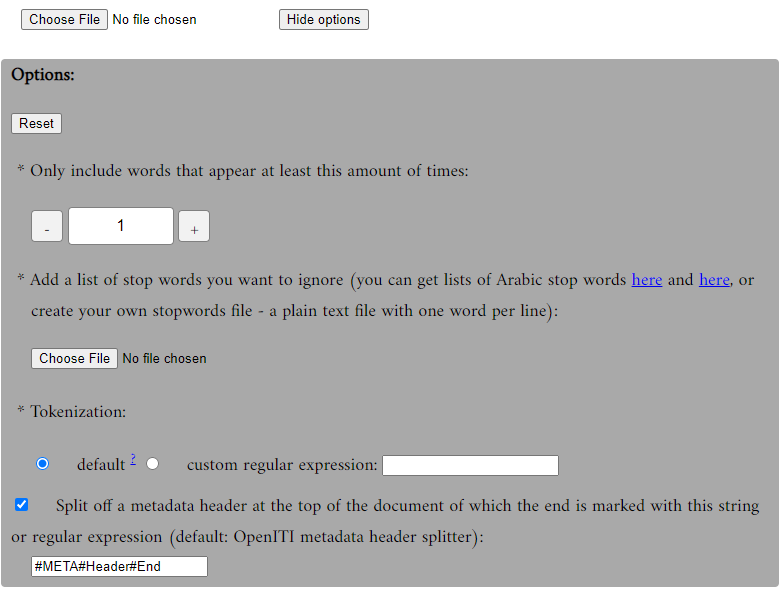
This was a really quick build; if you would find more options useful, don’t hesitate to contact me!
A cautionary note about tokens
The tool extracts ‘tokens’ from the text and counts them. The word ‘token’ is frequently used as a synonym for ‘word’, but they are not exactly the same. A token is nothing more than a sequence of characters, in our case defined by default as an unbroken sequence of Arabic-script characters, bounded on either side by characters that do not belong to that list of characters (there are other ways to define tokens as well). The tool does not try to analyse this sequence of characters as a word with a specific meaning, a specific form of a specific verb or the like.
For example, the token ولكتابه (wa-li-kitabi-hi, ‘and for his book’) could be considered four separate words, but the tool considers it one token. The opposite is also true: the name ʿAbd Allah is written in Arabic using two separate tokens (in our definition), ʿAbd and Allah, and both are thus counted separately.
Moreover, the plural of كتاب kitab is كتب kutub, and both are considered (and counted as) separate tokens by the tool, although they are arguably the same word. This problem is compounded with verbs, since Arabic expresses their number, gender, tense and so on using prefixes and suffixes. Each form of the same verb is thus considered a separate token.
This means that if you’re interested in how many times an author used a specific ‘word’ in the text, you may have to sum up a large number of different versions of the word.
For example, if we want to know how many times Ibn ʿAsakir uses the word kitab in his Taʾrikh madinat Dimashq, we could try to sum up the counts for these tokens:
| count | token |
| 3560 | كتب |
| 2585 | كتاب |
| 1805 | كتابه |
| 1320 | الكتاب |
| 1204 | فكتب |
| 1111 | وكتب |
| 492 | كتابا |
| 278 | بكتاب |
| 276 | الكتب |
| 263 | كتبه |
| 196 | كتابي |
| 150 | كتابيهما |
| 108 | بالكتاب |
| 103 | كتبنا |
| 96 | كتبهم |
| 91 | وكتبه |
| 87 | كتابك |
| 87 | كتبا |
| 81 | وكتاب |
| 50 | بكتابه |
| 47 | لكتاب |
| 40 | والكتاب |
| 39 | كتبي |
| 35 | كتبها |
| 29 | بكتب |
| 27 | كتابنا |
| 20 | وكتبنا |
| 20 | كتابها |
| 19 | فكتبه |
| 19 | الكتابين |
| 16 | بالكتب |
| 15 | بكتابك |
| 14 | فكتبنا |
| 13 | كتابهم |
| 12 | بكتابي |
| 12 | فكتبها |
| 11 | ولكتابه |
| 10 | كتبك |
| 10 | كتابكم |
| 9 | كتابهما |
| 9 | للكتب |
| 9 | والكتب |
| 8 | كتبكم |
| 7 | وكتبا |
| 7 | وكتبهم |
| 6 | فكتبا |
| 6 | وكتابه |
| 6 | كتابين |
| 5 | لكتابه |
| 5 | بكتبه |
| 4 | للكتاب |
| 4 | فالكتاب |
| 4 | وكتابا |
| 4 | وكتبها |
| 4 | لكتبه |
| 4 | بكتابة |
| 4 | لكتب |
| 4 | وبكتاب |
| 3 | بكتابهم |
| 3 | وبالكتاب |
| 3 | وبكتابك |
| 3 | وكتبهما |
| 3 | بكتبي |
| 3 | وكتابي |
| 3 | أفبكتاب |
| 2 | كتبهن |
| 2 | وكتبي |
| 2 | والكتابان |
| 2 | فكتاب |
| 2 | بكتابين |
| 2 | بكتبك |
| 2 | كتابان |
| 2 | أكتاب |
| 2 | وبكتابه |
| 2 | كالكتاب |
| 2 | قرأالكتاب |
| 2 | وكتابها |
| 1 | الكتبا |
| 1 | وكتابهم |
| 1 | وكتابك |
| 1 | والكتابين |
| 1 | بكتبكم |
| 1 | كتباه |
| 1 | بكتابكم |
| 1 | بالكتابين |
| 1 | كتابى |
| 1 | وكتبك |
| 1 | الكتبات |
| 1 | قرأكتاب |
| 1 | الكتابان |
| 1 | أقرألكتاب |
| 1 | ككتابكم |
| 1 | فكتابك |
| 1 | تصنيفكتاب |
| 1 | والكتبا |
| 1 | بهذاالكتاب |
| 1 | كتابنه |
| 1 | واكتابي |
| 1 | فقرأكتاب |
| 1 | ولكتابك |
| 1 | وإنماالكتاب |
| 1 | لكتابك |
But even that approach is not always successful. For example, the word kataba (‘he wrote’) and the word kutub (‘books’) are clearly separate words, but they are written in exactly the same way in unvocalised Arabic (كتب) and are thus considered to be one token, and counted as such.
It is impossible to know from the frequency list how often the token كتب refers to a book and how often to the act of writing. By way of illustration, I have marked in bold the cases in the table where there is uncertainty over whether the verb or the noun is used.
The example also shows another use case for such frequency lists: it shows a number of tokens that are clearly errors in the text, often due to the omission of a space (marked in bold and italics in the table); these all appear only once or twice in the text. Combining such frequency information for all texts in the corpus could give us an idea of what tokens in our texts are likely to be errors and should be flagged as such. We are currently experimenting with the use of such frequency lists of single tokens (and of token bigrams – combinations of two adjacent tokens) extracted from the entire OpenITI corpus for identifying possible OCR mistakes in texts produced by the OCR pipeline we are setting up to get additional texts into the corpus. More about this in a later blog post!
Appendix: list of Unicode characters
By default, the tool considers any sequence of the following unicode characters a token:
-
ء ARABIC LETTER HAMZA
-
آ ARABIC LETTER ALEF WITH MADDA ABOVE
-
أ ARABIC LETTER ALEF WITH HAMZA ABOVE
-
ؤ ARABIC LETTER WAW WITH HAMZA ABOVE
-
إ ARABIC LETTER ALEF WITH HAMZA BELOW
-
ئ ARABIC LETTER YEH WITH HAMZA ABOVE
-
ا ARABIC LETTER ALEF
-
ب ARABIC LETTER BEH
-
ة ARABIC LETTER TEH MARBUTA
-
ت ARABIC LETTER TEH
-
ث ARABIC LETTER THEH
-
ج ARABIC LETTER JEEM
-
ح ARABIC LETTER HAH
-
خ ARABIC LETTER KHAH
-
د ARABIC LETTER DAL
-
ذ ARABIC LETTER THAL
-
ر ARABIC LETTER REH
-
ز ARABIC LETTER ZAIN
-
س ARABIC LETTER SEEN
-
ش ARABIC LETTER SHEEN
-
ص ARABIC LETTER SAD
-
ض ARABIC LETTER DAD
-
ط ARABIC LETTER TAH
-
ظ ARABIC LETTER ZAH
-
ع ARABIC LETTER AIN
-
غ ARABIC LETTER GHAIN
-
ف ARABIC LETTER FEH
-
ق ARABIC LETTER QAF
-
ك ARABIC LETTER KAF
-
ل ARABIC LETTER LAM
-
م ARABIC LETTER MEEM
-
ن ARABIC LETTER NOON
-
ه ARABIC LETTER HEH
-
و ARABIC LETTER WAW
-
ى ARABIC LETTER ALEF MAKSURA
-
ي ARABIC LETTER YEH
-
ً ARABIC FATHATAN
-
ٌ ARABIC DAMMATAN
-
ٍ ARABIC KASRATAN
-
َ ARABIC FATHA
-
ُ ARABIC DAMMA
-
ِ ARABIC KASRA
-
ّ ARABIC SHADDA
-
ْ ARABIC SUKUN
-
ٰ ARABIC LETTER SUPERSCRIPT ALEF
-
ـ ARABIC TATWEEL
-
٠ ARABIC-INDIC DIGIT ZERO
-
١ ARABIC-INDIC DIGIT ONE
-
٢ ARABIC-INDIC DIGIT TWO
-
٣ ARABIC-INDIC DIGIT THREE
-
٤ ARABIC-INDIC DIGIT FOUR
-
٥ ARABIC-INDIC DIGIT FIVE
-
٦ ARABIC-INDIC DIGIT SIX
-
٧ ARABIC-INDIC DIGIT SEVEN
-
٨ ARABIC-INDIC DIGIT EIGHT
-
٩ ARABIC-INDIC DIGIT NINE
-
ٮ ARABIC LETTER DOTLESS BEH
-
ٹ ARABIC LETTER TTEH
-
پ ARABIC LETTER PEH
-
چ ARABIC LETTER TCHEH
-
ژ ARABIC LETTER JEH
-
ک ARABIC LETTER KEHEH
-
گ ARABIC LETTER GAF
-
ی ARABIC LETTER FARSI YEH
-
ے ARABIC LETTER YEH BARREE
-
۱ EXTENDED ARABIC-INDIC DIGIT ONE
-
۲ EXTENDED ARABIC-INDIC DIGIT TWO
-
۳ EXTENDED ARABIC-INDIC DIGIT THREE
-
۴ EXTENDED ARABIC-INDIC DIGIT FOUR
-
۵ EXTENDED ARABIC-INDIC DIGIT FIVE
-
۶ EXTENDED ARABIC-INDIC DIGIT SIX
-
۷ EXTENDED ARABIC-INDIC DIGIT SEVEN
-
۸ EXTENDED ARABIC-INDIC DIGIT EIGHT
-
۹ EXTENDED ARABIC-INDIC DIGIT NINE
-
۰ EXTENDED ARABIC-INDIC DIGIT ZERO